5月25日下午不到2点,今天,柯洁再度迎战AlphaGo。比赛依旧从上午10点半开始,在经历了第一场的1/4子落败后,柯洁在第二盘中盘落败AlphaGo。这是本次中国乌镇围棋大赛中柯洁对战AlphaGo三场比赛中的第二场,也正式宣告了本次人机大赛的结局--人类落败。但由于本次以“三番棋”形式下棋,输赢都将下满三场,因此本周六还将会有第三场的比赛。 
和第一场比赛相比,柯洁似乎紧张很多,在开场30分钟就提前进入了“抓头发”状态 AlphaGo是由谷歌旗下DeepMind团队的戴密斯·哈萨比斯、大卫·席尔瓦、黄士杰等开发的一款人工智能程序。2016年3月,AlphaGo曾以4:1战胜韩国棋手李世石,成为第一个击败人类职业围棋选手的电脑程序。2016年12月底,AlphaGo身披“Master”马甲,5天内横扫中日韩棋坛,最终以60场连胜纪录告退。 一、“1/4子” 第二局虽然中盘落败,但是第一局输了1/4子,乍看都不多,是否意味着对战双方只存在细微的能力差距,人类稍加努力就能迎头赶上呢? 不是的。 (第一场比赛) 在第一场赛后,柯洁曾坦言,自己就知道要输1/4子,AlphaGo每步棋都是匀速,在最后单官阶段也是如此,所以自己有时间点目,看清输1/4子了。 作为电脑程序,DeepMind团队给AlphaGo设定的目标是“去赢”,而不是“去赢得更多目数”。打个比方,因此如果在下A处时有99.9%的几率能够赢得1/4子,而在下B处时有99.8%的几率能够赢得10子,AlphaGo将会选1/4子而不是10子。 因此,AlphaGo将会使用最稳妥的方法保证自己能赢,哪怕这意味着以最小的差距取得胜利--1/4子。 二、“新狗”与“老狗” 为了以示区分,DeepMind团队将去年战胜李世石的“老狗”称为AlphaGo Lee,将战胜李世石的“新狗”称为AlphaGo Master,取自年初时横扫棋坛的马甲“Master”。 大家可能下意识地觉得,程序迭代升级,必然意味着计算能力的大大提升。上一代AlphaGo配备了50个TPU(张量处理单元,Tensor Processing Unit,可以理解成谷歌专门为机器学习打造的芯片),可以向下搜索50步棋,这一代少说没有100个不好意思见人吧? AlphaGo缘何如此“聪明”和超乎人类的思考和反应能力? 就在AlphaGo与柯洁“人机大战”不久前,Google I/O 2017 大会上,谷歌“移动为先”向“AI优先”再次升级,其中最典型的表现之一就是更新升级了去年公布的TPU(Tensor Processing Unit),一款谷歌自己高度定制化的AI(针对AI算法,例如其自己开发的Tensor Flow深度学习架构)芯片。
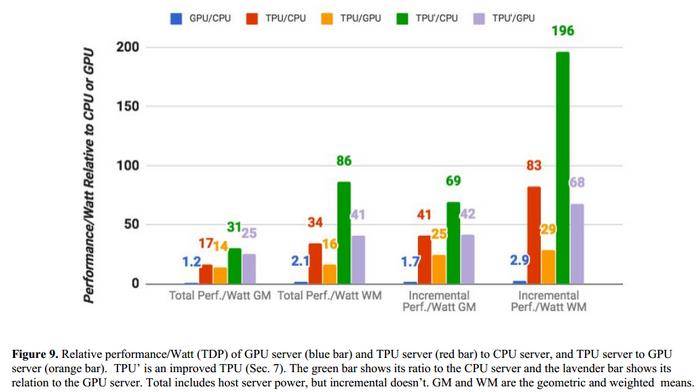
这款芯片也是AlphaGo背后的功臣,即AlphaGo能以超人的熟练度下围棋都要靠训练神经网络来完成,而这又需要计算能力(硬件越强大,得到的结果越快),TPU就充当了这个角色,更重要的是借此显现出了在AI芯片领域相对于英特尔CPU和英伟达GPU的优势。何以见得? 在去年的“人机大战”中,起初AlphaGo的硬件平台采用的是CPU+GPU,即AlphaGo的完整版本使用了40个搜索线程,运行在48块CPU和8块GPU上,AlphaGo的分布式版本则利用了更多的芯片,40个搜索线程运行在1202块CPU和176块GPU上。 这个配置是和当时樊麾比赛时使用的,所以当时李世石看到AlphaGo与樊麾的对弈过程后,对“人机大战”很有信心。但是就在短短几个月时间内,谷歌就把运行AlphaGo的硬件平台切换到了TPU上,之后对战的结果是AlphaGo以绝对优势击败了李世石。也就是说,采用TPU之后的AlphaGo的运算速度和反应更快。那么究竟TPU与CPU和GPU相比,到底有多大的优势(例如性能和功耗)? 据谷歌披露的相关文件显示,其TPU与服务器级的英特尔Haswell CPU和英伟达K80 GPU进行比较,这些硬件都在同一时期部署在同个数据中心。测试负载为基于TensorFlow框架的高级描述,应用于实际产品的NN应用程序(MLP,CNN和LSTM),这些应用代表了数据中心承载的95%的NN推理需求。 尽管在一些应用上利用率很低,但TPU平均比当前的GPU或CPU快15~30倍,性能功耗比(TOPS/Watt)高出约30~80倍。此外,在TPU中采用GPU常用的GDDR5存储器能使性能TPOS指标再高3倍,并将能效比指标TOPS/Watt提高到GPU的70倍,CPU的200倍。
尽管英伟达对于上述的测试表示了异议,但TPU相对于CPU和GPU存在的性能功耗比的优势(不仅体现在AI,还有数据中心)已经成为业内的共识。值得一提的是,在刚刚举办Google I/O 2017 大会上发布的新一代TPU已经达到每秒180万亿次的浮点运算性能,超过了英伟达刚刚推出的GPU Tesla2 V100每秒120万亿次浮点运算性能。那么是什么造就TPU的优势?英伟达CEO黄仁勋表示,谷歌第二代TPU每秒可处理45万亿次浮点运算,而英伟达最新GPU(代号为“Volta”)每秒处理的浮点运算可达120万亿次。不久,谷歌将允许第三方开发者使用Cloud TPU,每个Cloud TPU将在含有四个TPU的主板上进行操作,提供总计180万亿次的每秒浮点运算。 简单来说,CPU是基于完全通用的诉求,实现的通用处理架构。GPU则主要基于图像处理的诉求,降低了一部分通用性,并针对核心逻辑做了一定的优化,是一款准通用的处理架构,以牺牲通用性为代价,在特定场合拥有比CPU快得多的处理效率。 而TPU,则针对更明确的目标和处理逻辑,进行更直接的硬件优化,以彻底牺牲通用性为代价,获得在特定场合和应用的极端效率,也就是俗话所言的“万能工具的效率永远比不上专用工具”。而这正好迎合了当下诸多炙手可热的人工智能的训练和推理等均需要大量、快速的数据运算的需求。 到目前为止,谷歌的TPU已经应用在各种领域的应用中,例如谷歌图像搜索(Google Image Search)、谷歌照片(Google Photo)、谷歌云视觉API(Google Cloud Vision API)、谷歌翻译以及AlphaGo的围棋系统中。实际上我们上述提到的Google I/O 2017大会推出和更新的诸多AI产品和服务背后均有TPU的硬件支持。 当然,我们在此并非否认CPU和GPU在AI中的作用,例如鉴于CPU的通用性,其灵活性最大,不仅可以运行各种各样的程序,也包括使用各种软件库的深度学习网络执行的学习和推理。GPU虽然不像 CPU那样通用和灵活,但它在深度学习计算方面更好,因为它能够执行学习和推理,并且不局限于单个的软件库。相比之下,TPU则几乎没有灵活性,并且只能在自家的TensorFlow中效率最高,这也是为何谷歌对外声称TPU不对外销售,且仍会继续采用CPU和GPU。在最近谷歌的2017年I/O开发者大会上,谷歌CEO Sundar Pichai还宣布推出了下一代TPU,对深度学习的训练性能及应用/推理性能都进行了优化。但是本次AlphaGo使用的依旧是上一代的TPU,而且短期内谷歌应该不太可能向公众出售配有TPU芯片、主板、或是服务器。这一代AlphaGo的配置了4块TPU。 但谷歌的这一做法印证了一个芯片产业的发展趋势,即在AI负载和应用所占数据中心比重越来越大的今天和未来,像谷歌、微软、Facebook、亚马逊、阿里巴巴、腾讯等这些数据中心芯片采购的大户,其之前对于CPU和GPU的通用性需求可能会越来越少,而针对AI开发应用的兼顾性能和能效的定制化芯片需求则会越来越多。 AlphaGo团队负责人Dave Silver表示,“AlphaGo Master是一个新版本的AlphaGo,我们非常努力地去改进了它的基础算法。算法比(用来训练的)数据量、计算能力都更为重要……和去年李世石版本的AlphaGo相比,AlphaGo Master只用了10%的计算能力,并且只训练了几周时间,不像之前需要训练数月。” AlphaGo Master的一大创新点就是它更多地依赖于自我学习。在这个版本中,AlphaGo实际上成为了它自己的老师,从它自己的现有经验中搜索中获得结果,和上一个版本相比大大减少了对人类现成经验(棋谱)的依赖(relies much less actually on human data),但并不是完全脱离了人类经验。 在比赛首日,搜狗公司CEO王小川曾经就AlphaGo和柯洁的人机大战发表了看法,其中有这样一段话:“根据公开资料推测,此次AlphaGo2.0的技术原理与之前有着巨大不同:1、放弃了监督学习,没有再用人的3000万局棋谱进行训练。” 这是一个非常容易引起误导的描述,而事实证明也确实引起了不少误导。甚至到现场时,有人向DeepMind创始人兼CEO Demis Hassabis问出了这样一个问题--“这次的AlphaGo是纯净版的AlphaGo吗?也就是说,它是否是完全不依赖人类大师的棋谱来自我学习的?” (DeepMind创始人兼CEO Demis Hassabis) Demis Hassabis听到这个问题时的眼神非常迷茫……他是这样回答的,“我不太确定我真的完全明白了这个问题,但是……你知道的,很明显,AlphaGo需要先从人类经验里学习,然后(这个版本的AlphaGo)更加依赖从自我博弈中学习。” 原文“I’m not sure if I understand the question correctly, but… You know… Obviously this version AlphaGo initially learns from human games, and then most of its learning now is from its own play against itself.” AlphaGo并不是完全脱离了人类棋谱、完全不使用监督学习,只是更加依赖于自我学习的数据来成长。其实这种“学习棋谱+自我博弈”的模式在上一代AlphaGo中已经得到了使用,这一代只是将重心侧重到了后者上而已。 退一万步来讲,没有人类棋谱的经验,AlphaGo连围棋的规则、概念、下法都不知道,谈何战胜世界冠军? 四、这么多“学习”,究竟是啥? 监督学习、无监督学习、深度学习、增强学习……这一个个翻译过来的计算机名词让人听得云里雾里,再加上“神经网络”、“机器学习”、“人工智能”那么它们具体是什么意思呢? 首先可以将监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)看作一对。监督学习给机器一些标注数据,将这些标注作为“监督”(结果好/坏的评判标准),接着让机器学习一个好的函数,从而对未知数据作出决策。非监督学习就是给机器不带标注的数据,让机器自己学会分类评判。 比如你将一张车的图片给机器看,并且告诉它这是车,下次它就会说出“车”。如果你给他展现出一张狗,它还说车,你就告诉它“你错了,这是狗。”久而久之的,它在“车”和“狗”的图像分辨中就能做得越来越好,原理其实很简单,但是对数据量的要求非常大。 接着我们可以将深度学习(Deep Learning)和增强学习(Reinforcement Learning,也译作“强化学习”)看作一对。深度学习现在大多用的大部分还是监督学习的方式,AlphaGo在学习棋谱的过程中使用的也是监督学习,类似上文中“车”和“狗”分类的例子。增强学习不像传统的监督学习,但也不能分类为无监督学习。在增强学习中,相当于你不告诉机器下一步怎么走,等它随机执行了一轮操作后,如果结果是好的,那么给它奖励,如果结果是不好的,那么给它惩罚,但是不告诉它哪一步做错了,久而久之机器会自己摸索出一套最佳方案来。 至于卷积神经网络(Convolutional Neural Network,CNN)则是深度学习的一种,安排深度学习的深层架构可以通过是直接堆叠,也可以通过卷积神经网络。 机器学习(Machine Learning)则是这些学习的总称,顾名思义就是让机器学会学习。 人工智能(Artificial Intelligence)是更大的一个范畴,包括感知智能、认知智能、运动智能等等。 五、逐渐兴起的增强学习 DeepMind团队当时选择更多地依靠增强学习来训练AlphaGo,减少对人类棋谱的依赖,其目的之一就是增加AlphaGo的泛化能力,使它变得更为通用,从而能被应用在围棋以外的领域上。 现在学术界的一个较为主流的观点是,训练机器进行增强学习需要建立一个世界模拟器(World Simulator),模拟真实世界的逻辑、原理、物理定律等。 想象一下,人类在电脑里打造了一个完全虚拟的世界,里面天是蓝的、地是实的、重力会将你抓牢……当你在这个世界里造出一个机器人来,只有婴儿刚出生时的体力,不会走,甚至不会爬,将它放进这个世界里不断刺激、不断训练,会发生什么? 这个机器人将会逐渐学会爬行、站立、奔跑,整个过程中人类只提供了一个初始参数,其他所有的训练都是靠这个机器人在环境中一次次的试错中。 拿OpenAI为例,OpenAI是Elon Musk于2015年12月宣布成立的非盈利AI项目,主要关注增强学习和无监督学习,科研人员会将大部分研究成果开源共享。5月15日,OpenAI发布了一款名为“Roboschool”的开源软件,用于训练机器。在这个虚拟环境中,科学家们还原了重力、摩擦力、加速度等不同元素。 不过,由于真实世界太过复杂,存在大量的表征学习参数,想要打造出一个完全一模一样的虚拟世界几乎不可能,人类甚至连实际世界的1/10复杂都无法模拟出来。因此现在的世界模拟器但集中在步骤可能性较少、任务行为较窄的领域(比如围棋、简单物理运动等)。 英伟达CEO黄仁勋在月初的GTC大会上也宣布了一款名为ISAAC的增强学习世界模拟器,创造出一个完全虚拟的、专为训练机器人而打造的世界,用来训练机器人执行打冰球、打高尔夫等动作。 在现实生活中,你想要训练一台机器学会打冰球,你要将这个冰球放在机器前面,一遍一遍地教会它,成千上万次的训练都耗费大量的时间。然而在虚拟世界里,机器可以在一秒内重复众多次这样的动作,不需要遵循现实世界中的时间法则。 而且你还可以同时训练一堆机器学习打球,然后找到里面最聪明的一个,将它的“大脑”程序复制出来,创建一堆同样的机器再继续训练筛选,听起来真的很可怕对不对…… 无论是从围棋的竞技体育意义、还是人工智能的现实落地意义,都已经逐渐被娱乐意义所取代。 人工智能的应用方方面面,从已经初步落地的安防、医疗、智能家居等行业应用,到陆续举办的围棋大赛大赛、AI写诗、AI唱歌等宣传活动,应有尽有。人类已经在享受挑战超越人类自身能力极限带来的巨大快乐之中,从驯化动植物到工具的发明与创造,人类便突破了速度与力量的局限,至阿波罗登月开始,人类摆脱了地球的引力限制,而这一次乃至人工智能的每一次的狂欢,人类都沉浸在探索智慧终极奥秘的乐趣之中,这件事本身就非常有意思。 |

 |
 |
|申请友链|网址导航|网站导航|小黑屋|扫一下二维码进入手机版|祈安网 ( 闽ICP备06000414号-7 )|公安备案号35052402000130
GMT+8, 2024-9-17 03:50 , Processed in 0.800084 second(s), 49 queries , Gzip On.