谷歌人工智能阿尔法go与韩国顶尖围棋选手李世石的“人机大战”在韩国首尔展开第三局的较量。李世石没能挽回赛点,执黑中盘再次失利,在五番棋的较量中总比分0-3落败,错失百万美元奖金,号称人类智力竞技“最后高地”的围棋运动沦陷。阿尔法go已经取得了3:0的绝对优势,这也意味着,在正常五局三胜的规则下完败。根据谷歌与李世石之间的协议,双方必须下满五番棋,今天李世石的行棋不在畏首畏尾,但破釜沉舟还是难求一胜。双方第四局比赛将于北京时间明天进行,李世石将为荣誉而战。
李世石黑子 第一局
第二局
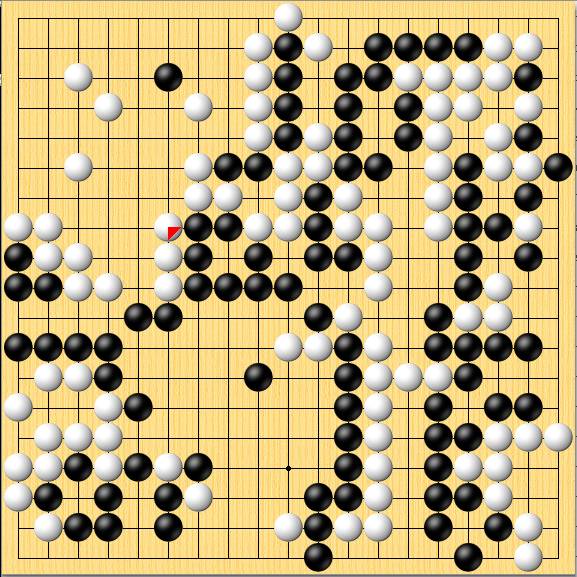
李世石黑子 第三局 棋类游戏一直被视为顶级人类智力的试金石。人工智能与人类棋手的对抗一直在上演,此前在三子棋、跳棋和国际象棋等棋类上,计算机程序都曾打败过人类,从上世纪90年代中期战胜全世界跳棋顶尖高手的Chinook程序,到IBM公司研发的超级计算机“深蓝”在1997年第一次战胜了国际象棋冠军卡斯巴罗夫。 但相比拥有2500多年历史的围棋而言,国际象棋的算法要简单的多。围棋每回合的可能性更多,共有250种可能,一盘棋可以长达150回合。同时,围棋有3^361种局面,而可观测到的宇宙,原子数量才10^80。 按照技术的发展速度,一般认为至少还需要10年才能实现人工智能才能在围棋是上战胜人类职业选手,所以AlphaGo此次能否战胜李世石有着历史性的意义。 AlphaGo到底是什么 AlphaGo并不是普通意义上的智能机器人,而是一个拥有自我学习和进化能力的智能系统。 AlphaGo的核心是两种不同的深度神经网络--“决策网络”(policy network)和“价值网络”(Value network)。其中,“决策网络”负责减少搜索宽度,排除明显的错误,选择下一步走法;“价值网络”则负责减少搜索深度,通过对局势的判断,在明显劣势下果断抛弃某些路线,不用每条道算到黑。 AlphaGo工作原理详解: 在国际象棋中,计算机可以靠计算速度战胜人类,但围棋更复杂,也被认为是无法战胜人类的领域,所以AlphaGO要和李世石进行挑战。 据DeepMInd公司首席执行官兼谷歌副总裁戴米斯·哈萨比斯(Demis Hassabis)透露,DeepMind为AlphaGo输入了海量的职业棋手对局,其自我演绎的对局数更是达到了3000万局。 戴密斯·哈萨比斯称,AlphaGO以无数的棋谱数据为基础进行深度学习,不断完善,又通过自我模拟比赛提高实力,比赛前又针对性地进行了很多测试,这几个月里AlphaGO的围棋水平得到了显著的提高。 按照戴密斯·哈萨比斯的说法,AlphaGO的优势在于它有两个神经网络: 第一个神经网络:观察棋盘布局,找到最佳的下一步,原理是预测每一个合法下一步的胜算概率。 第二大神经网络:预测每一个棋手赢棋的可能,分析未来局面的“好”与“坏”,去决定怎么改变。 通过这两个网络分析局面,AlphaGo会更像一个人类棋手,会在下棋时分析每一步的风险系数,比如在未来20步的N种情况下,它立即就能判断出如何落子的胜率最高。 |

 |
 |
|申请友链|网址导航|网站导航|小黑屋|扫一下二维码进入手机版|祈安网 ( 闽ICP备06000414号-7 )|公安备案号35052402000130
GMT+8, 2024-4-20 18:37 , Processed in 0.697862 second(s), 49 queries , Gzip On.